
Autor: Fabian Meyer, inovex GmbH
Searching large text corpora is an almost trivial task in 2022. Distributed, high-performance databases search thousands of texts in seconds, looking for keywords, places or names. But what if we don’t know exactly how the information we are looking for was stored?
We from the Service-Meister research project have stumbled across the problem that we want to provide service technicians with information on service calls, such as repairs and maintenance, from old reports. However, these old reports are not filled out in a standardised way: While technician A writes: “Display was defective, used spare part XYZ”, technician B writes: “Screen broken, replaced XYZ”. The information we are looking for is that “Replace XYZ” seems to fix the problem, and is present in both texts. For a human, of course, it is easy to see that both reports describe the same problem and, therefore, the same solution, but for computers this is more difficult.
However, it is immediately obvious that certain keywords are simply replaced by synonyms so that the content remains semantically identical. Since, as mentioned at the beginning, we can search our text database without any problems, selected parts of the queries are to be extended by automatically generated synonyms. This way, we can find more relevant reports and make them available to the technicians.
The problem
Most people can easily recognise, understand and use synonyms in their mother tongue. Thesauri have existed for ages, calculated in computer time, which can also do this. It only gets more complicated in a language domain of its own, with neologisms and special meanings of individual words.
To illustrate this, here is an example from our project: KROHNE, our partner at Service-Meister, for example, uses the Optiflux 4400, an electromagnetic flowmeter that is almost identical to the Optiflux 3400 and structurally also very related to the Waterflux. So it may help to add “3400” and “Waterflux” to a search for Optiflux 4400 display defective and see if a display has been repaired on another Optiflux or Waterflux in the past to get helpful information. We use Elasticsearch as our search engine, which allows us to combine search terms with AND/OR links: The original search Optiflux 4400 defect then becomes the following search query through automatically generated synonyms:
(Optiflux OR Waterflux) AND (4400 OR 3400) AND (defective OR broken OR not working)
The OR means that one or more of the terms in a group must occur, an AND means that one word from each of the groups must occur. Elasticsearch offers this option out of the box and searches our 15,000 documents in a few moments. This leaves us with the task of searching for meaningful synonyms.
Automatically generated synonyms
Basically, there are three approaches to automatically generate or find synonyms, since they are, in principle, already present in the language:
Dictionary-based
The best-known way is to use a dictionary. This will get you surprisingly far, but it only works (without further ado) for individual words. Since you can’t check how “similar” the synonyms really are, you have to be careful – especially when building new sentences with the synonyms. If you change two words in a sentence that are not “perfect” synonyms, you may well change the content. Small example? To like and to want are listed as synonyms, as are colleague and co-worker.
Relevant Ressources: Openthesaurus, Wordnet [1]
SSynonyms using Statistical Language Models (SLM)
The basic idea is that words are represented by the context in which they appear, usually in the form of so-called embeddings. If words always appear in similar contexts, as is to be expected with synonyms, then this representation should be very similar. Similarity in embeddings is usually measured in cosine similarity.
One can then simply look for the most similar word among all known words and, according to the theory, it should have a close semantic relationship to the original word. However, this relationship does not necessarily mean “synonymous”; also, for example, different inflections of words often have very similar embeddings.
Roughly, methods of this approach can be divided into two families: those that use contextual SLMs (like BERT [2]) and those that use “classical” SLMs (like Word2Vec [3]). The former have the advantage that used context tends to find better synonyms, since they are naturally very dependent on it. However, they have the disadvantage that training and searching for synonyms is much more time-consuming.
If you are interested in the difference between contextual and traditional embeddings, you can find a great overview article here. Different methods on the topic of automatically generated synonyms with this approach can be found, for example, in this current survey [4].
Translation Graphs
Here, bilingual dictionaries are used to find synonyms. Here, too, there are many different implementations, but translations of a word are generally searched for and then translated back into the source language. Since translations are often in the form 1:n, i.e. a word has at least one, but usually several translations, you get several results. If you then translate these words back into the source language, you get a lot of potential synonyms.
Concrete implementations of this look can like the following example: The authors of [5] extend this approach to further levels and stop when the original word is reached again. Or more formally: Let a be a word in language A and e a word in language E and A→E a translation from A to E . Then synonyms are defined as follows: If there is a cyclic graph of the form (a1→e1→a2→e3→a1) then the sets {a1,a2,a3} and {e1,e2,e3} are candidates for synonyms.
Since bilingual dictionaries are readily available resources for the majority of spoken languages and no computation is usually involved, this and related approaches can be implemented very efficiently.
Extensibility of the approaches
Since we are looking for automatically generated synonyms in our own language domain, the approaches must be extendable. For thesauri and WordNets, this is possible manually in any case. WordNets, however, are usually algorithmically generated so that, with sufficiently large resources, they could also be extended automatically. The same applies to approaches based on statistical language models. However, since these usually have a fixed vocabulary, it may be necessary to extend this – a new training of the entire model is then necessary. In general, this is, of course, feasible, but especially for contextual models like BERT it is expensive inmany respects.
Expanding translation graphs does not make sense in this context, as the vocabulary has to be more or less expanded to include proper names.
Selected approach
We have chosen an embedding-based approach [6], which is based on Word2Vec. The paper presents good results (more on this in the Evaluation section), but the algorithm and the model are still simple and quick to train or implement and easy to follow. In principle, a synonymous word s is searched for a target word t, which is both similar to t and similar to the current context c of t. If, for example, a synonym for “acquire” is searched for that appears in the context of “company”, then the influence of the context would ensure that the closest neighbour of “acquire” is not selected (here in the example “learn”) but “buy”, which has a higher overall similarity to t and c. This may sound complicated at first, but the following graphic shows the example in a visual form so that it is easier to understand:

For similarity, the paper presents the following four measures of substitution, which control for the influence of context c on s:
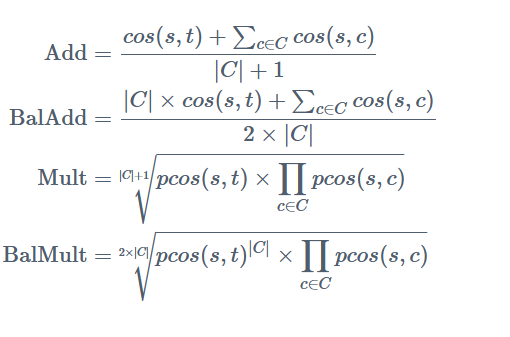
Each of these has its own advantages and disadvantages, which are briefly explained in the paper. Still, in general, it tries to incorporate the context more or less into the final result, and you are well advised to try them all.
Adaptation
The original uses Word2Vecf [7], a dependency-based variant of Word2Vec. Nevertheless, we use the latter because, firstly, we did not find an implementation for it, and a replica would have exceeded the time frame, and the differences do not look significant at first glance. More about whether this was a good decision later. In general, however, the “normal” Word2Vec should also work, because words that are in a similar context also get similar embeddings here – even if these then reflect “functional rather than topic relationships” [6].
So we train a Word2Vec model using Wikipedia dumps, German news corpora (see [8]) and our domain-specific corpora consisting of extracted service manuals for Krohne products and the reports mentioned above. The training runs for a few hours on our cluster, the results look promising, here you can see the ten most similar words to the German word for defect, “Defekt”:
| Rank | Word | Cosine similarity |
| 1. – 4. | defect[s] | 0.8270 – 0.7323 |
| 5. | short circuit | 0.6960 |
| 6. | malfunction | 0.6574 |
| 7. | due to defect | 0.6114 |
| 8. | material defects | 0.6074 |
| 9. | technical defect | 0.6040 |
| 10. | failure | 0.5983 |
The four most similar words are all variations of the target itself. The following ones, however, already show the strength of SLM: material defect and short circuit are hyponyms of defect in our domain, i.e. subtypes of defects that can occur in the components. So far, so good!
Evaluation of automatically generated synonyms
This is where the really difficult part starts, because there is no standardised procedure to check the quality of synonyms. This is especially true for the German language, because for English there would be a SemEval Task [9], which is used as a benchmark in the paper. But since we are just interested in synonyms in our domain (and language), this does not help much. So we have no choice but to create a test set manually.
Different hyperparameter settings of Word2Vec as well as various preprocessing steps and the substitution measures of the synonym algorithm are evaluated. Since, theoretically, one has to try every word of the vocabulary as candidate c, it is also evaluated whether it is sufficient to use the most similar n to check words. The similarity search itself is very efficient due to the Word2Vec implementation (Gensim), so that we can potentially save a lot of time in later productive use.
So the evaluation process looks like this: We collect a set of words and think about what would be a suitable context that could come up in the field. Then we try to qualitatively evaluate the automatically generated synonyms, although this can be problematic as a layperson. We then do the whole thing for the different Word2Vec models, as well as different n candidates (between 100 and 10,000) and the four substitution measures. We did not carry out a quantitative evaluation, as we could only have compared the results with the dictionary-based synonyms – which have the problems mentioned and do not really make sense as a benchmark. After all, if these are supposed to serve as a gold standard against which we compare, why don’t we just use them?
Results
Service-Meister Domain
In principle, the chosen approach works. The described most similar search in Word2Vec always displays words that make sense from a human point of view, i.e. that are closely related to our target t. For example, the most similar words to car are: motorbike, vehicle, bicycle, cars, taxi and bus. The example illustrates the problem quite well: some words are synonyms, some have the same hypernym (in the example, this would be means of transport), but it is a synonym list and certainly not a complete list. The addition of context cannot improve this, as the following tables show.
Since substitution measure Add (1) and BalAdd (2) and Mult (3) and BalMult (4) usually have identical results, they are summarised. Target describes the word for which synonyms are searched; context, the respective context.
| Target | Context | Metric 1+2 | Metric 3+4 | Most Similar |
| optiflux | defective | 2100c | ifc3000 | tidalflux |
| optiflux | not available | reach | reach | tidalflux |
| display | defective | loose contact | loose contact | displays |
| Target | Context | Metric 1+2 | Metric 3+4 | Most Similar |
| optiflux | screen, defect, contact | 2100c | ifc100 | tidalflux |
| tidalflux | screen, defect, contact | junction box | board | tidalflux |
| gerät | screen, defect, contact | sensor | sensor | devices |
This small excerpt already indicates that no good synonyms are found by means of the algorithm, because the influence of the context ensured that the words became too dissimilar. Maybe the Word2Vecf model would have been better here, but we have not (yet) evaluated it.
With the most-similar search, on the other hand, we always get similar words, even if it is sometimes just a different inflection – but, of course, this can still be filtered or solved in a preprocessing step.
Mit der Most-Similar-Suche hingegen bekommen wir immer ähnliche Wörter, auch wenn es manchmal nur eine andere Flexion ist – was man aber natürlich noch filtern oder in einem Preprocessing-Schritt lösen kann.
German language domain
This impression is also confirmed outside our domain, as the following example shows
| Target | Context | Metric 1+2 | Metric 3+4 | Most Similar |
| beautiful | solved | just | just | pretty |
| elegant | solved | supple | effective | stylish |
| simply | solved | solve | solve | sometimes |
In the case of the target elegantly solved in context, however, we also see for the first time that the context has the right influence and forms a better substitute than the most-similar function. Sometimes it does work as described in the paper.
But even this positive example does not change the general impression and our decision: If we look at the ten most-similar terms, we come across graceful, light-footed, refined, filigree and casual, i.e. a whole series of synonyms, so that in our view it makes more sense to focus on filtering these results in a meaningful way than to continue to tinker with the algorithm.
Learnings
Automatically generated synonyms are a surprisingly complex and active field of research and, for individual words, it is not a big problem to find synonyms by machine. It becomes difficult when context plays an important role and our special case; a domain of its own. This ensures that all dictionary approaches have to be expanded manually, which is time-consuming on the one hand and requires expert knowledge in the domain on the other.
The SLM approaches then depend on re-training, which is not so easy to do on existing hardware, especially with more recent approaches. In addition, it is difficult to evaluate the results without simply manually creating a complete list of desired synonyms.
What I personally take away is that it is extremely important to think hard about how you want to evaluate your solutions from the beginning, to find or create resources for this and to determine metrics, if this is possible. Otherwise, you quickly work by feel, tuning parameters based on that feel and a test set with a big bias, so that progress is increasingly difficult to measure and you can quickly move in the wrong direction.
Since, in the end, the simple most-similar approach helped us the most, I also felt very reminded of what my computer science professor has been trying to teach me since the first semester: Keep It Simple, Stupid!
Literatur
[1] Fellbaum, Christiane (2005). WordNet and wordnets. In: Brown, Keith et al. (eds.), Encyclopedia of Language and Linguistics, Second Edition, Oxford: Elsevier, 665-670.
[2] Kenton, Jacob, Devlin Ming-Wei Chang, and Lee Kristina Toutanova. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” Proceedings of NAACL-HLT. 2019.
[3] Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
[4] E. Naser-Karajah, N. Arman and M. Jarrar, “Current Trends and Approaches in Synonyms Extraction: Potential Adaptation to Arabic,” 2021 International Conference on Information Technology (ICIT), 2021, pp. 428-434.
[5] Jarrar, Mustafa, et al. “Extracting Synonyms from Bilingual Dictionaries.” Proceedings of the 11th Global Wordnet Conference. 2021.
[6] Melamud, O., Levy, O., & Dagan, I. (2015, June). A simple word embedding model for lexical substitution. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing (pp. 1-7).
[7] Levy, O., & Goldberg, Y. (2014, June). Dependency-based word embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) (pp. 302-308).
[8] https://github.com/devmount/GermanWordEmbeddings
[9] Carlo Strapparava and Rada Mihalcea. 2007. SemEval-2007 Task 14: Affective Text. In Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), pages 70-74, Prague, Czech Republic. Association for Computational Linguistics.
You liked this article? Then subscribe to our newsletter and receive regular updates on similar topics and the Project Service-Meister and discuss with us about this and similar exciting topics in our LinkedIn Group.