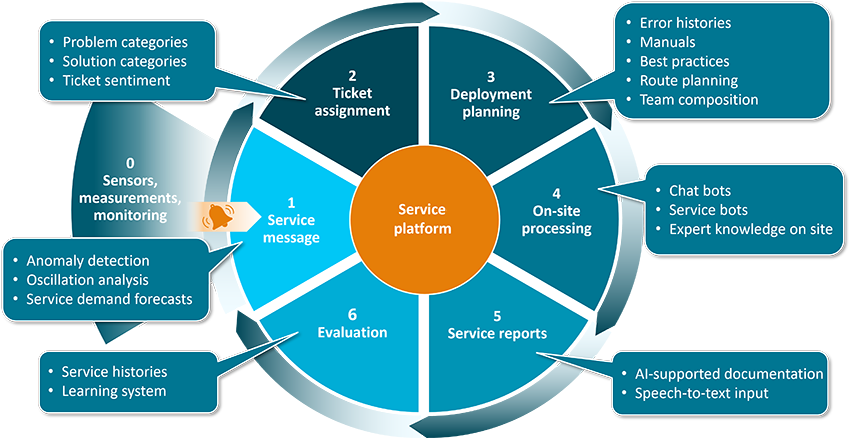
We will show you practical application possibilities, techniques and prerequisites for your established processes. This allows you, for example, to see for yourself which data sources you need and which you already have. By hovering over the sections and keywords, the respective insight is shown: for example, more information on ‘service demand forecasts’ is shown when you hover with the mouse over ‘service notification’.