
Autor: Fabian Meyer, inovex GmbH
Das Durchsuchen großer Textkorpora ist im Jahr 2022 eine fast schon triviale Aufgabe. Verteilte, hochperformante Datenbanken durchsuchen in sekundenschnelle tausende Texte auf der Suche nach Schlagwörtern, Orten oder Namen. Was ist aber, wenn wir gar nicht so genau wissen, wie gesuchte Informationen genau gespeichert wurden?
Wir vom Forschungsprojekt Service-Meister sind über das Problem gestolpert, dass wir Servicetechniker:innen Informationen zu Serviceeinsätzen, wie Reparaturen und Wartungen, aus alten Reports zur Verfügung stellen wollen. Diese alten Reports sind allerdings nicht standardisiert ausgefüllt: Während Technikerin A schreibt: „Display war defekt, habe Ersatzteil XYZ benutzt”, schreibt Techniker B: „Bildschirm kaputt, XYZ ausgetauscht”. Die Information, die wir suchen, ist, dass „XYZ“ austauschen scheinbar das Problem behebt, und ist in beiden Texten vorhanden. Für einen Menschen ist natürlich leicht zu sehen, dass beide Reports das gleiche Problem und daher auch die gleiche Lösung beschreiben, für Computer ist das schon schwieriger.
Es springt aber sofort ins Auge, dass gewisse Keywords einfach durch Synonyme ausgetauscht sind, sodass der Inhalt semantisch identisch bleibt. Da wir, wie eingangs erwähnt, unsere Textdatenbank problemlos durchsuchen können, sollen ausgewählte Teile der Anfragen durch automatisch generierte Synonyme erweitert werden. So können wir mehr relevante Reports finden und den Techniker:innen zur Verfügung stellen.
Die Problemstellung
Die meisten Menschen können in ihrer Muttersprache problemlos Synonyme erkennen, verstehen und nutzen. Schon seit Ewigkeiten, in Computerzeit gerechnet, gibt es Thesauri, die dies ebenfalls beherrschen. Komplizierter wird es erst in einer eigenen Sprachdomäne, mit Neologismen und speziellen Bedeutungen einzelner Wörter.
Um das zu verdeutlichen, hier ein Beispiel aus unserem Projekt: KROHNE, unser Partner bei Service-Meister, benutzt beispielsweise den Optiflux 4400, ein magnetisch-induktives Durchflussmessgerät, das fast identisch zum Optiflux 3400 ist und baulich auch sehr verwandt mit dem Waterflux. Es kann also durchaus helfen, eine Suche nach Optiflux 4400 Display defekt um „3400” und „Waterflux” zu erweitern und zu schauen, ob in der Vergangenheit bereits ein Display bei einem anderen Optiflux oder Waterflux repariert wurde um so an hilfreiche Informationen zu kommen. Als Search Engine nutzen wir Elasticsearch, was uns erlaubt, Suchbegriffe mit AND/OR – Verknüpfungen zu kombinieren: Aus der ursprünglichen Suche Optiflux 4400 defekt wird dann durch automatisch generierte Synonyme folgende Suchanfrage:
(Optiflux OR Waterflux) AND (4400 OR 3400) AND (defekt OR kaputt OR funktioniert nicht)
Das OR bedeutet, einer oder mehrere der Begriffe einer Gruppe müssen vorkommen, ein AND bedeutet, dass aus jeder der Gruppen ein Wort vorkommen muss. Elasticsearch bietet diese Option von Haus aus und durchsucht in wenigen Augenblicken unsere 15.000 Dokumente. Damit bleibt für uns die Aufgabe, sinnvolle Synonyme zu suchen.
Automatisch generierte Synonyme
Grundsätzlich gibt es drei Ansätze, um Synonyme automatisch zu generieren oder zu finden, da sie ja prinzipiell in der Sprache schon vorhanden sind:
Wörterbuch-basiert
Der wohl bekannteste Weg ist es, ein Wörterbuch zu benutzen. Damit kommt man schon überraschend weit, aber das funktioniert (ohne Weiteres) erstmal nur für einzelne Wörter. Da man auch nicht kontrollieren kann, wie „ähnlich” sich die Synonyme denn nun wirklich sind, gilt es, vorsichtig zu sein – gerade wenn man neue Sätze mit den Synonymen baut. Wenn man in einem Satz zwei Wörter verändert, die keine „perfekten” Synonyme sind, kann man schon durchaus den Inhalt ändern. Kleines Beispiel? Mögen und Wollen sind als Synonyme verzeichnet, genauso wie Kumpel und Mitarbeiter.
Relevante Ressourcen: Openthesaurus, Wordnet [1]
Synonyme mittels Statistical Language Models (SLM)
Die grundsätzliche Idee ist, dass Wörter durch den Kontext, in dem sie auftauchen, repräsentiert werden, meist in Form sogenannter Embeddings. Wenn Wörter nun immer in ähnlichen Kontexten auftauchen, wie es bei Synonymen zu erwarten ist, dann sollte diese Repräsentation also sehr ähnlich sein. Ähnlichkeit wird bei Embeddings üblicherweise in Kosinus-Ähnlichkeit gemessen.
Man kann dann einfach unter allen bekannten Wörtern das ähnlichste Wort suchen, und es sollte, so die Theorie, eine enge semantische Verwandtschaft zum ursprünglichen Wort haben. Diese Verwandtschaft muss allerdings nicht zwangsläufig „synonym” bedeuten, auch haben beispielsweise unterschiedliche Flexionen von Worten oft sehr ähnliche Embeddings.
Grob kann man Methoden dieses Ansatzes in zwei Familien einteilen: jene, die kontextuelle SLMs (wie BERT [2]) nutzen und solche, die „klassische” SLMs (wie Word2Vec [3]) nutzen. Erstere haben den Vorteil, dass genutzter Kontext tendenziell bessere Synonyme finden kann, da diese natürlich sehr von diesem abhängig sind. Sie haben jedoch den Nachteil, dass Training und Suche von Synonymen deutlich aufwendiger sind.
Wer sich genauer für den Unterschied von kontextuellen und traditionellen Embeddings interessiert, findet unter anderem hier einen tollen Übersichtsartikel dazu. Unterschiedliche Methoden zum Thema automatisch generierte Synonyme mit diesem Ansatz gibt es zum Beispiel in dieser aktuellen Survey [4].
Translation Graphs
Hier werden bilinguale Wörterbücher verwendet um Synonyme zu finden. Es gibt auch hier viele verschiedene Implementierungen, generell aber werden Übersetzungen eines Wortes gesucht und diese dann wieder in die Ausgangssprache übersetzt. Da Übersetzungen häufig der Form 1:n sind, sprich ein Wort hat mindestens eine, meist aber mehrere Übersetzungen, erhält man so mehrere Ergebnisse. Übersetzt man diese Worte dann wieder zurück in die Ausgangssprache, erhält man eine Menge an potentiellen Synonymen.
Konkrete Implementationen davon sehen dann z. B. wie folgt aus: Die Autoren von [5] erweitern diesen Ansatz um weitere Levels und stoppen, wenn das Ursprungswort wieder erreicht wird. Oder formaler ausgedrückt: Sei a ein Wort in Sprache A und e ein Wort in Sprache E und A→E eine Übersetzung von A nach E . Dann sind Synonyme wie folgt definiert: Gibt es einen zyklischen Graphen der Form (a1→e1→a2→e2→a3→e3→a1) dann sind die Sets {a1,a2,a3} und {e1,e2,e3}
Kandidaten für Synonyme.
Da bilinguale Wörterbücher für den Großteil an gesprochenen Sprachen leicht verfügbare Ressourcen sind und man i.d.R keine Berechnungen durchgeführt werden, sind dieser und verwandte Ansätze sehr effizient implementierbar.
Erweiterbarkeit der Ansätze
Da wir automatisch generierte Synonyme in unserer eigenen Sprachdomände such, müssen die Ansätze erweiterbar sein. Für Thesauri und Wordnets dies manuell in jedem Fall möglich. WordNets sind in der Regel allerdings algorithmisch generiert, sodass man mit ausreichend großen Ressourcen diese auch automatisch erweitern könnte. Gleiches gilt für Ansätze basierend auf Statistical Language Models. Da diese in der Regel aber ein fixes Vokabular haben, kann es sein, dass man dieses erweitern muss – ein neues Training des gesamten Modells ist dann notwendig. Generell ist das natürlich machbar, aber gerade für kontextuelle Modelle wie BERT ist es in vielerlei Hinsicht teuer.
Translation Graphs zu erweitern macht in diesem Kontext keinen Sinn, da das Vokabular mehr oder weniger um Eigennamen erweitert werden muss.
Ausgewählter Ansatz
Wir haben einen Embedding-basierten Ansatz [6] gewählt, der auf Word2Vec basiert. Im Paper werden gute Ergebnisse präsentiert (mehr dazu im Abschnitt Evaluation), der Algorithmus und das Modell sind aber trotzdem einfach und schnell zu trainieren bzw. implementieren und gut nachvollziehbar.
Im Prinzip wird zu einem Target-Wort t ein synonymes Wort s gesucht, das sowohl ähnlich zu t ist als auch ähnlich zum aktuellen Kontext c von t. Wenn zum Beispiel ein Synonym für „acquire” gesucht wird, das im Kontext von „company” auftaucht, dann würde der Einfluss des Kontexts dafür sorgen, dass nicht der nächste Nachbar von „acquire” ausgewählt wird (hier im Beispiel „learn”) sondern „buy”, das in Summe eine höhere Ähnlichkeit zu t und c hat. Klingt vielleicht erstmal kompliziert, aber in der folgenden Grafik sieht man das Beispiel bildlich dargestellt, sodass es einfacher zu verstehen ist:

Für Ähnlichkeit werden im Paper die vier folgenden Substituierungsmaße präsentiert, mit denen der Einfluss des Kontexts c auf s kontrolliert wir:
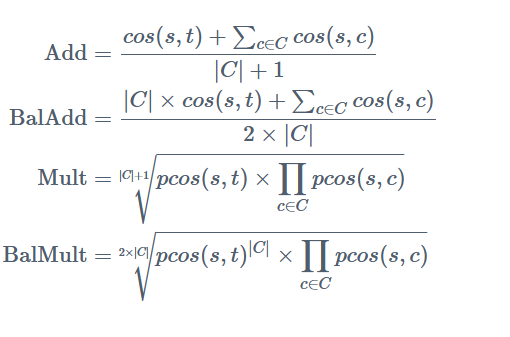
Jede hiervon hat eigene Vor- und Nachteile, die im Paper kurz erläutert werden, generell wird aber probiert, den Kontext stärker oder schwächer in das Endergebnis mit einzubeziehen und man ist gut damit beraten, alle auszuprobieren.
Adaption
Im Original wird Word2Vecf [7] verwendet, eine dependency-based Variante von Word2Vec. Wir nutzen trotzdem letzteres, da wir erstens keine Implementation hierzu gefunden haben, und ein Nachbau den zeitlichen Rahmen gesprengt hätte und die Unterschiede auf den ersten Blick nicht signifikant aussehen. Ob das eine gute Entscheidung war, dazu später mehr. Generell sollte aber auch das „normale” Word2Vec funktionieren, denn auch hier bekommen Worte, die in ähnlichem Kontext stehen, ähnliche Embeddings – auch wenn diese dann eher „funktionelle anstatt topic Relationship widerspiegeln” [6].
Wir trainieren also ein Word2Vec-Modell und nutzen hierzu wir Wikipedia Dumps, German News Corpora (siehe [8]) und unsere domänenspezifischen Korpora, bestehend aus extrahierten Service Manuals für Krohne-Produkte und den erwähnten Reports. Das Training läuft wenige Stunden auf unserem Cluster, die Ergebnisse sehen vielversprechend aus, hier sieht man beispielhaft die zehn ähnlichsten Wörter zu defekt:
| Rang | Wort | Cosinus-Ähnlichkeit |
| 1. – 4. | defekt[e, er, es] | 0.8270 – 0.7323 |
| 5. | kurzschluss | 0.6960 |
| 6. | fehlfunktion | 0.6574 |
| 7. | wegen defekten | 0.6114 |
| 8. | materialfehler | 0.6074 |
| 9. | technischer defekt | 0.6040 |
| 10. | ausfall | 0.5983 |
Die ähnlichsten vier Worte sind allesamt Abwandlungen vom Target selbst. Die darauffolgenden zeigen allerdings schon die Stärke von SLM: Materialfehler und Kurzschluss sind Hyponyme von defekt in unserer Domäne, also Unterarten von Defekten, die an den Bauteilen auftreten können. So weit, so gut!
Evaluation automatisch generierter Synonyme
Hier fängt der wirklich schwierige Teil an, da es kein standardisiertes Verfahren gibt, um die Qualität von Synonymen zu prüfen. Das gilt insbesondere für die deutsche Sprache, denn für Englisch gäbe es einen SemEval Task [9], der im Paper als Benchmark genutzt wird. Da wir aber gerade an Synonymen in unserer Domäne (und Sprache) interessiert sind, hilft das nicht viel weiter. Es bleibt also nichts anderes übrig, als manuell ein Testset zu erstellen.
Evaluiert werden verschiedene Hyperparameter-Settings von Word2Vec sowie diverse Preprocessing-Schritte und die Substituierungsmaße des Synonym-Algorithmus. Da man, theoretisch gesehen, jedes Wort des Vokabulars als Kandidat c ausprobieren muss, wird ebenfalls evaluiert, ob es ausreicht, die ähnlichsten n
Wörter zu checken. Die Ähnlichkeitssuche selbst ist aufgrund der genutzten Word2Vec-Implementation (Gensim) sehr effizient, sodass wir hier potentiell viel Zeit im späteren Produktiveinsatz sparen können.
Die Evaluation sah also wie folgt aus: Wir sammeln ein Set von Wörtern und überlegen, was ein passender Kontext wäre, der im Feldeinsatz auftauchen könnte. Dann versuchen wir, die automatisch generierten Synonyme qualitativ zu evaluieren, obwohl dass als Laie natürlich problematisch sein kann. Das Ganze machen wir dann für die unterschiedlichen Word2Vec-Modelle, sowie unterschiedliche n Kandidaten (zwischen 100 und 10.000) und die vier Substituierungsmaße. Eine quantitative Evaluation haben wir nicht vorgenommen, da wir hier lediglich mit den Ergebnissen von den dictionary-based Synonymen hätten vergleichen können – die ja aber genannte Probleme haben und als Benchmark auch nicht wirklich Sinn machen. Denn wenn diese als Goldstandard dienen sollen gegen den wir vergleichen, wieso benutzen wir sie dann nicht einfach?
Ergebnisse
Service-Meister-Domäne
Prinzipiell funktioniert der gewählte Ansatz. Die beschriebene most similar-Suche in Word2Vec zeigt immer Wörter an, die aus menschlicher Sicht Sinn ergeben, also eng verwandt mit unserem Target t
sind. Zum Beispiel sind die most similar Worte zu Auto: Motorrad, Fahrzeug, Fahrrad, Autos, PKW und Bus. Das Beispiel illustriert das Problem ganz gut: Manche Wörter sind Synonyme, manche haben das gleiche Hypernym (im Beispiel wäre dies Fortbewegungsmittel), es ist aber Synonymliste und schon gar keine vollständige Liste. Die Erweiterung um Kontext kann dies nicht verbessern, wie die folgenden Tabellen zeigt.
Da Substituierungsmaß Add (1) und BalAdd (2) und Mult (3) und BalMult (4) meist identische Ergebnisse haben, sind diese zusammengefasst. Target beschreibt das Wort, für das Synonyme gesucht werden, Kontext den jeweiligen Kontext.
| Target | Kontext | Metric 1+2 | Metric 3+4 | Most Similar |
| optiflux | defekt | 2100c | ifc3000 | tidalflux |
| optiflux | nicht erreichbar | erreichen | erreichen | tidalflux |
| display | defekt | wackelkontakt | wackelkontakt | displays |
| Target | Kontext | Metric 1+2 | Metric 3+4 | Most Similar |
| optiflux | bildschirm, defekt, kontakt | 2100c | ifc100 | tidalflux |
| tidalflux | bildschirm, defekt, kontakt | anschlussdose | platine | tidalflux |
| gerät | bildschirm, defekt, kontakt | sensor | sensor | geräte |
Schon dieser kleine Auszug deutet an, dass keine guten Synonyme mittels des Algorithmus gefunden werden, da der Einfluss des Kontext dafür sorgte, dass die Wörter sich zu unähnlich wurden. Eventuell wäre das Word2Vecf-Modell hier doch besser gewesen, das haben wir allerdings (noch) nicht evaluiert.
Mit der Most-Similar-Suche hingegen bekommen wir immer ähnliche Wörter, auch wenn es manchmal nur eine andere Flexion ist – was man aber natürlich noch filtern oder in einem Preprocessing-Schritt lösen kann.
Deutsche Sprachdomäne
Auch außerhalb unserer Domäne bestätigt sich dieser Eindruck, wie folgendes Beispiel zeigt:
| Target | Kontext | Metric 1+2 | Metric 3+4 | Most Similar |
| schoen | gelöst | eben | eben | hübsch |
| elegant | gelöst | geschmeidig | wirkende | stilsicher |
| einfach | gelöst | lösen | lösen | manchmal |
Bei dem Target elegant im Kontext gelöst sehen wir allerdings auch das erste Mal, dass der Kontext den richtigen Einfluss hat und ein besseres Substitut bildet als die Most-Similar-Funktion. Manchmal funktioniert es wohl doch so, wie im Paper beschrieben.
Auch dieses positive Beispiel ändert aber nichts am generellen Eindruck und unserer Entscheidung: Betrachtet man die zehn Most-Similar-Begriffe, stößt man neben geschmeidig noch auf anmutig, leichtfüssig, raffiniert, filigran und lässig, also auf eine ganze Reihe von Synonymen, sodass es aus unserer Sicht mehr Sinn macht, sich darauf zu fokussieren, diese Ergebnisse sinnvoll zu filtern, als weiter am Algorithmus zu schrauben.
Learnings
Automatisch generierte Synonyme sind ein überraschend komplexes und aktives Forschungsfeld und für einzelne Wörter ist es auch kein großes Problem, maschinell Synonyme zu finden. Schwierig wird es dann, wenn Kontext eine wichtige Rolle spielt und unserem Spezialfall; einer eigenen Domäne. Diese sorgt dafür, dass alle Wöterbuchansätze manuell erweitert werden müssen, was einerseits aufwendig ist und andererseits Expert:innenwissen in der Domäne erfordert.
Die SLM-Ansätze sind dann auf ein erneutes Training angewiesen, was gerade bei aktuelleren Ansätzen nicht mehr so einfach auf vorhandener Hardware durchführbar ist. Hinzu kommt, dass man die Ergebnisse schwer evaluieren kann, ohne einfach manuell eine vollständige Liste an gewünschten Synonymen zu erstellen.
Was ich persönlich mitnehme: Es ist extrem wichtig, sich von vornherein intensiv Gedanken darum zu machen, wie man seine Lösungen evaluieren will, Ressourcen hierfür sucht oder erstellt und Metriken bestimmt, sofern dies eben möglich ist. Sonst arbeitet man schnell nach Gefühl, tuned Parameter basierend auf diesem Gefühl und einem Testset mit großem Bias, sodass der Fortschritt immer schwieriger zu messen ist und man sich schnell in die falsche Richtung bewegen kann.
Da uns am Ende der simple Most-Similar-Ansatz am meisten geholfen hat, fühlte ich mich auch sehr an das erinnert, was mein Informatik-Professor mir seit dem ersten Semester beibringen will: Keep It Simple, Stupid!
Literatur
[1] Fellbaum, Christiane (2005). WordNet and wordnets. In: Brown, Keith et al. (eds.), Encyclopedia of Language and Linguistics, Second Edition, Oxford: Elsevier, 665-670.
[2] Kenton, Jacob, Devlin Ming-Wei Chang, and Lee Kristina Toutanova. „BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.“ Proceedings of NAACL-HLT. 2019.
[3] Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
[4] E. Naser-Karajah, N. Arman and M. Jarrar, „Current Trends and Approaches in Synonyms Extraction: Potential Adaptation to Arabic,“ 2021 International Conference on Information Technology (ICIT), 2021, pp. 428-434
[5] Jarrar, Mustafa, et al. „Extracting Synonyms from Bilingual Dictionaries.“ Proceedings of the 11th Global Wordnet Conference. 2021.
[6] Melamud, O., Levy, O., & Dagan, I. (2015, June). A simple word embedding model for lexical substitution. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing (pp. 1-7).
[7] Levy, O., & Goldberg, Y. (2014, June). Dependency-based word embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) (pp. 302-308).
[8] https://github.com/devmount/GermanWordEmbeddings
[9] Carlo Strapparava and Rada Mihalcea. 2007. SemEval-2007 Task 14: Affective Text. In Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), pages 70–74, Prague, Czech Republic. Association for Computational Linguistics.
Dieser Artikel hat Ihnen gefallen? Dann abonnieren Sie unseren Newsletter und erhalten Sie regelmäßige Updates zu ähnlichen Themen und zum Projekt Service-Meister und diskutieren Sie mit uns zu diesem und ähnlichen spannenden Themen in unserer LinkedIn Gruppe.